Dirichlet polynomials and entropy
Recently, we (David Spivak and Tim Hosgood) put a preprint on the arXiv called “Dirichlet polynomials and entropy”, which explains how to recover Shannon entropy from a rig homomorphism involving the weighted geometric mean. In this blog post, we explain the main story, from a slightly different point of view as found in the preprint: starting with Dirichlet polynomials, seeing how they corresponds to set-theoretic bundles, and then looking at how Huffman coding can help us to rediscover the notion of entropy.
Update. This paper has now been published: Dirichlet polynomials and entropy, Entropy 23 (2021), 1085. DOI: 10.3390/e23081085.
Recently, David Spivak and I put a preprint on the arXiv called “Dirichlet polynomials and entropy”, and I was lucky enough to get two minutes to speak about what we studied during the poster session at ACT 2021. However, we figured it might also be nice to write a little summary of the topic, presenting some of the main material but from a slightly different point of view — whence, this post! I’ll miss out quite a few details that can be found in the preprint (since otherwise this post would be far too long), so if anything seems to come out of thin air, or to be completely unjustified, then hopefully you can find some more answers on the arXiv version. But please don’t hesitate to post any questions in the comments!
The authors thank Marco Perin for useful conversations.
{kind=link}
1 Setting the scene
My background is rather far from applied category theory — my PhD was in homotopical methods in complex-analytic geometry (although I suppose you could argue that algebraic geometry was indeed the very first instance of “applied” category theory!) — but the more time I spend reading about lenses, polynomials functors, decorated cospans, and all these lovely things, the more I become enamoured with them. So when David told me that he’d been thinking about Dirichlet polynomials, I got rather excited: these are things that turn up in complex geometry, so maybe I can actually contribute something here! After the initial excitement, however, we quickly realised that the sort of Dirichlet polynomials that we were talking about were not particularly amenable to classical geometric methods, since they had strictly non-negative coefficients, for one thing. However, it turns out that, by restricting generality in this way, we gain access to some new ways of thinking about these objects. But before we get ahead of ourselves, let’s take a step back and look at some context.
Entropy was introduced by Shannon in his seminal paper on communication theory [1], and (roughly) tells us about the uncertainty inherent to the outcomes of some random variable: given a discrete random variable X, with possible outcomes x_1,\ldots,x_n, the entropy of X is defined to be H(X) = -\sum_{i=1}^{n} \mathbb{P}(X=x_i)\log\mathbb{P}(X=x_i) (where here, and throughout this post, \log=\log_2).
Since then, the field of information theory has flourished, and I am definitely not the person to give an overview of the garden of forking paths of stories that it has told. Instead, let me jump ahead just over 60 years, to when John Baez, Tobias Fritz, and Tom Leinster showed [2] how to understand entropy as “information loss”, in a categorical setting. Shortly after, John and Tobias gave a Bayesian interpretation of relative entropy (or Kullback–Liebler divergence) [3], thus laying more categorical foundations for studying entropy.
Half a decade on, in a seemingly unrelated paper, David (Spivak) and David Jaz Myers wrote about the topos of Dirichlet polynomials [4], relating them to set-theoretic bundles, and working parallel to the theory of polynomial functors. It is using this language, however, that we can develop an interesting theory, which turns out to link back to the story of categorical entropy. This is the approach that I’m going to take in this blog post: if we work with the “algebraic” structure of Dirichlet polynomials, can we naturally stumble upon the idea of entropy?
2 What are Dirichlet polynomials?
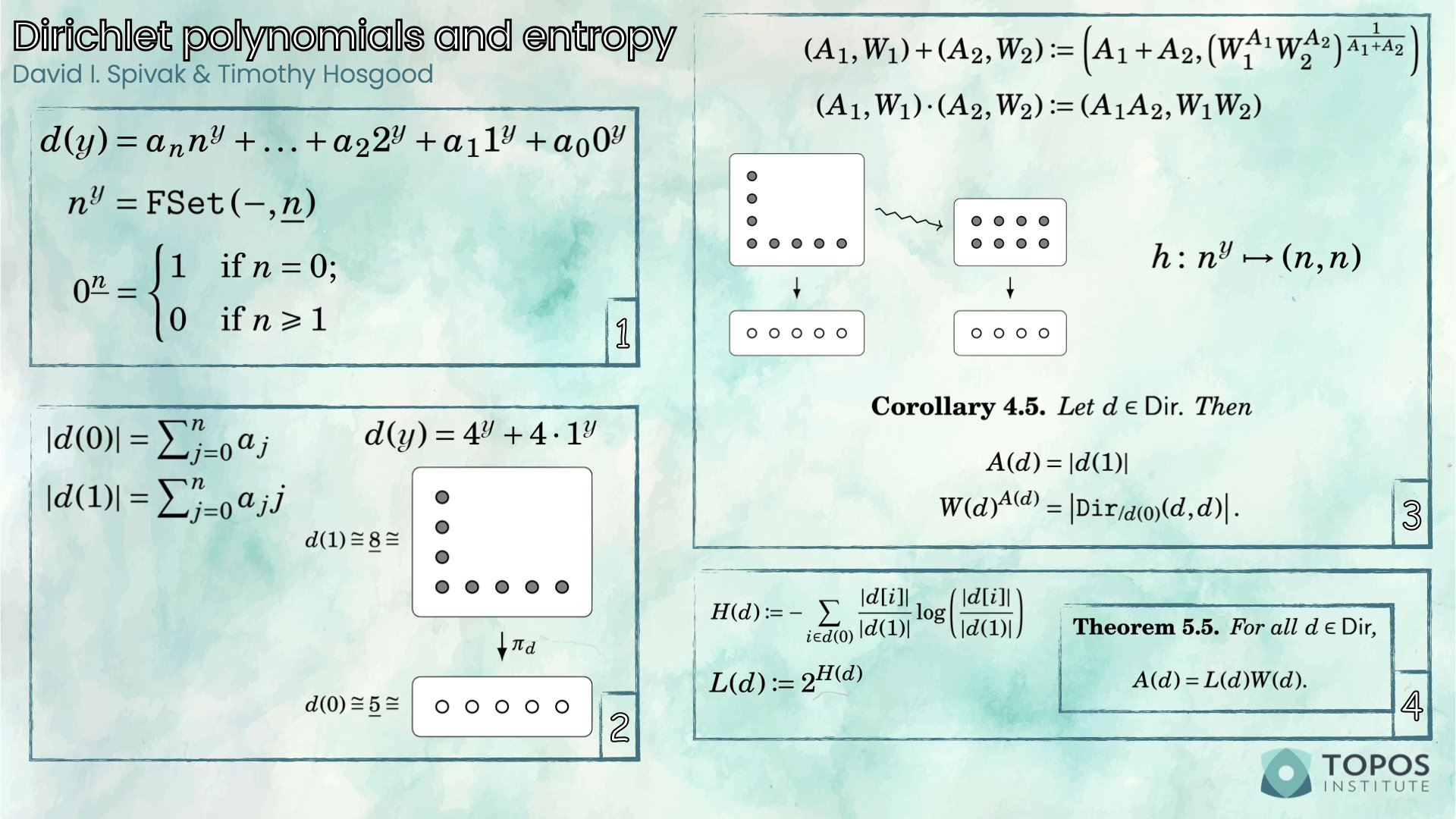
For us, a Dirichlet polynomial (in one variable, \mathcal{y}) is a “thing” of the form d(\mathcal{y}) = a_n\cdot n^\mathcal{y}+ \ldots + a_1 1^\mathcal{y}+ a_0 0^\mathcal{y} where n,a_0,\ldots,a_n\in\mathbb{N}. This looks just like a polynomial, but where the base and the exponent have been switched. Of course, we use \mathcal{y} instead of x for a good reason: we should be thinking of the Yoneda embedding. That is, we have a nice correspondence between finite sets and natural numbers, given by cardinality: let’s write \underline{n} to mean “the” finite set with n elements. Then we can think of n^\mathcal{y} as the Yoneda embedding of \underline{n} in the category \mathtt{FSet} of finite sets, i.e. n^\mathcal{y}= \mathtt{FSet}(-,\underline{n}) and then we can “plug in” any natural-number value for \mathcal{y} and get back a natural number: n^m = \mathtt{FSet}(\underline{m},\underline{n}) \longleftrightarrow n^m where, on the left, “n^m” really means “\underline{n}^{\underline{m}}”, and on the right it actually does mean “the natural number n^m”, but we’re going to be a bit lax with our notational pedantry and not really underline things (unless we really want to emphasise something), due to the wonderful fact that |\underline{n}^{\underline{m}}|=n^m.
But what then does n^\mathcal{y}+m^\mathcal{y} mean? And what about a_n\cdot n^\mathcal{y}? Well, these are just given by the coproduct in \mathtt{FSet}, which is disjoint union: a_n\cdot n^\mathcal{y}+ a_m\cdot m^\mathcal{y} = \left(\coprod_{i=1}^{a_n} \mathtt{FSet}(-,\underline{n})\right) \sqcup \left(\coprod_{i=1}^{a_m} \mathtt{FSet}(-,\underline{m})\right).
So when we said that Dirichlet polynomials were “things”, we really meant that they are functors d\colon\mathtt{FSet}^{\mathrm{op}}\to\mathtt{FSet}. Indeed, we could give this as the definition of Dirichlet polynomials: functors \mathtt{FSet}^{\mathrm{op}}\to\mathtt{FSet} given by coproducts of representables.
Before we go any further, it’s worth remarking that 0^\mathcal{y} is much more interesting than it might appear. More precisely, 0^\mathcal{y}\neq 0; in fact, 0^\mathcal{y} is a sort of Dirac delta function, since 0^{\underline{m}} = \begin{cases} 1 &\text{if }m=0\text{;} \\0 &\text{otherwise.} \end{cases} This is important when we multiply Dirichlet polynomials: you can show that d(\mathcal{y})\cdot 0^\mathcal{y} = d(0)\cdot 0^\mathcal{y}. But we haven’t actually said anything about multiplying these things yet, so let’s sort that out right now.
In fact, we can endow the set of Dirichlet polynomials with the structure of a rig (also known as a semiring), i.e. a ring without inverses. We write \mathsf{Dir} to denote this rig. The multiplicative identity is 1^\mathcal{y}, and the additive identity is 0, where we use the fact that we have an embedding of rigs \begin{aligned} \mathbb{N} &\hookrightarrow \mathsf{Dir} \\a &\mapsto a\cdot 1^\mathcal{y}. \end{aligned}
Before moving on and doing fun things with this rig, we note one nice lemma.
3 An interesting rig
Consider the set \mathbb{R}_{\geqslant0}\times\mathbb{R}_{\geqslant0} endowed with the following additive structure: (A_1,W_1) + (A_2,W_2) = \left(A_1+A_2, (W_1^{A_1}W_2^{A_2})^{\frac{1}{A_1+A_2}}\right) (our choice of notation for the components will become clear later on). That is, we simply add the first components, and then take a weighted geometric mean in the second component. If we define multiplication to be simply component-wise (i.e. (A_1,W_1)\cdot(A_2,W_2)=(A_1A_2,W_1W_2)), then we call the resulting rig the rectangle rig, and denote it by \mathsf{Rect}. We have given no justification for introducing this rig1, but hopefully it’ll soon become clear why it’s so interesting to us.
Given a Dirichlet polynomial d, we write h(d)=(A(d),W(d)), and call the two components area and width, respectively.
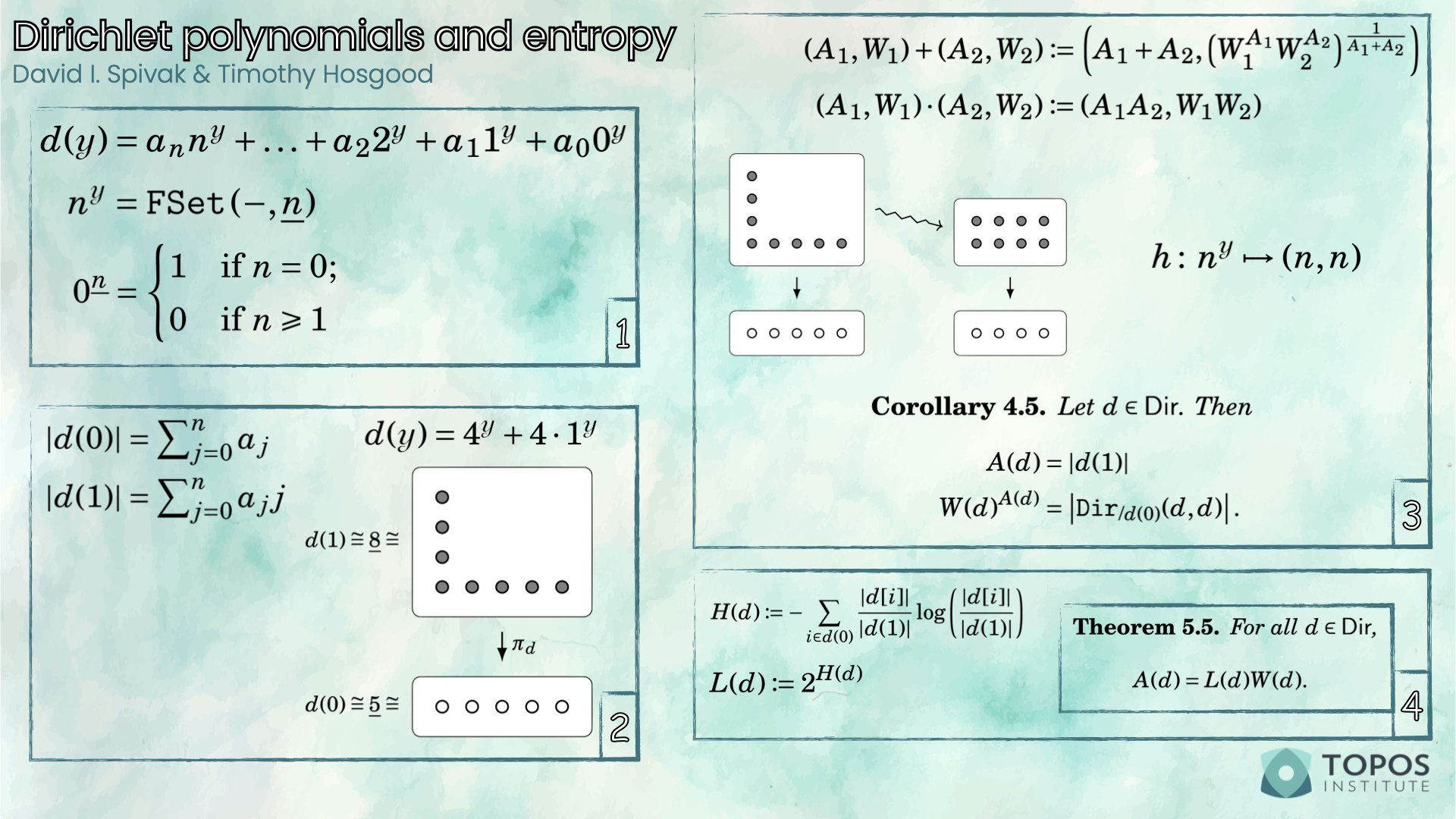
Let’s calculate an explicit example, say for d(\mathcal{y}) = 4^\mathcal{y}+ 4. Then \begin{aligned} h(d) &= h(4^\mathcal{y}) + h(4\cdot 1^\mathcal{y}) \\&= (4,4) + 4\cdot(1,1) \\&= (4,4) + \left(1+1+1+1, (1^1 1^1 1^1 1^1)^{\frac{1}{4}}\right) \\&= (4,4) + (4,1) \\&= \left(4+4, (4^4 1^4)^{\frac{1}{8}}\right) \\&= (8,2). \end{aligned} That is, the Dirichlet polynomial d(\mathcal{y})=4^\mathcal{y}+4 has area equal to 8 and width equal to 2. But what does this mean?
To answer this question, we turn to the correspondence between Dirichlet polynomials and bundles.
4 Bundles
Lots of people call lots of things “bundles”, so let’s be precise2 with what we mean here: a (set-theoretic) bundle is simply a function \pi\colon E\to B, where E,B\in\mathtt{FSet}.
Note that there is, in particular, a unique function !\colon\varnothing=\underline{0}\to\underline{1}=\{*\}. By functoriality, this induces, for any Dirichlet polynomial d\colon\mathtt{FSet}^{\mathrm{op}}\to\mathtt{FSet}, a function \pi_d=d(!)\colon d(1)\to d(0) of finite sets. Something that David and David proved [4, Theorem 4.6] is that this gives rise to an equivalence of categories between Dirichlet polynomials and set-theoretic bundles. Of course, we can’t even state this theorem yet, because we haven’t said what morphisms of Dirichlet polynomials should be, but they are simply natural transformations of functors; this theorem then says that a morphism \varphi\colon d\to e is exactly a pair of functions \varphi_1\colon d(1)\to e(1) and \varphi_0\colon d(0)\to e(0) such that the following diagram commutes: \begin{CD} d(1) @>{\varphi_1}>> e(1) \\@V{\pi_d}VV @VV{\pi_e}V \\d(0) @>>{\varphi_0}> e(0) \end{CD}
What is important to us is that we can study a Dirichlet polynomial d by studying the associated bundle \pi_d\colon d(1)\to d(0), and we’ve already given a nice formula for how to compute d(1) and d(0). In fact, we can even prove another interesting relation, linking back to Section 3.
OK, so now we have a lot of pieces of a puzzle that we can start trying to fit together. Let’s fix an explicit Dirichlet polynomial, say d(\mathcal{y})=4^\mathcal{y}+4 again. We know that this has a corresponding bundle: \pi_d\colon d(1)\to d(0), and we also know, from the Lemma at the end of §2, that |d(1)|=8 and |d(0)|=5 (but we now also know that |d(1)|=A(d), and we previously calculated that A(d)=8, so that’s good!). Of course, we can actually be a bit more precise and explain how the function \pi_d acts — let’s draw a picture.
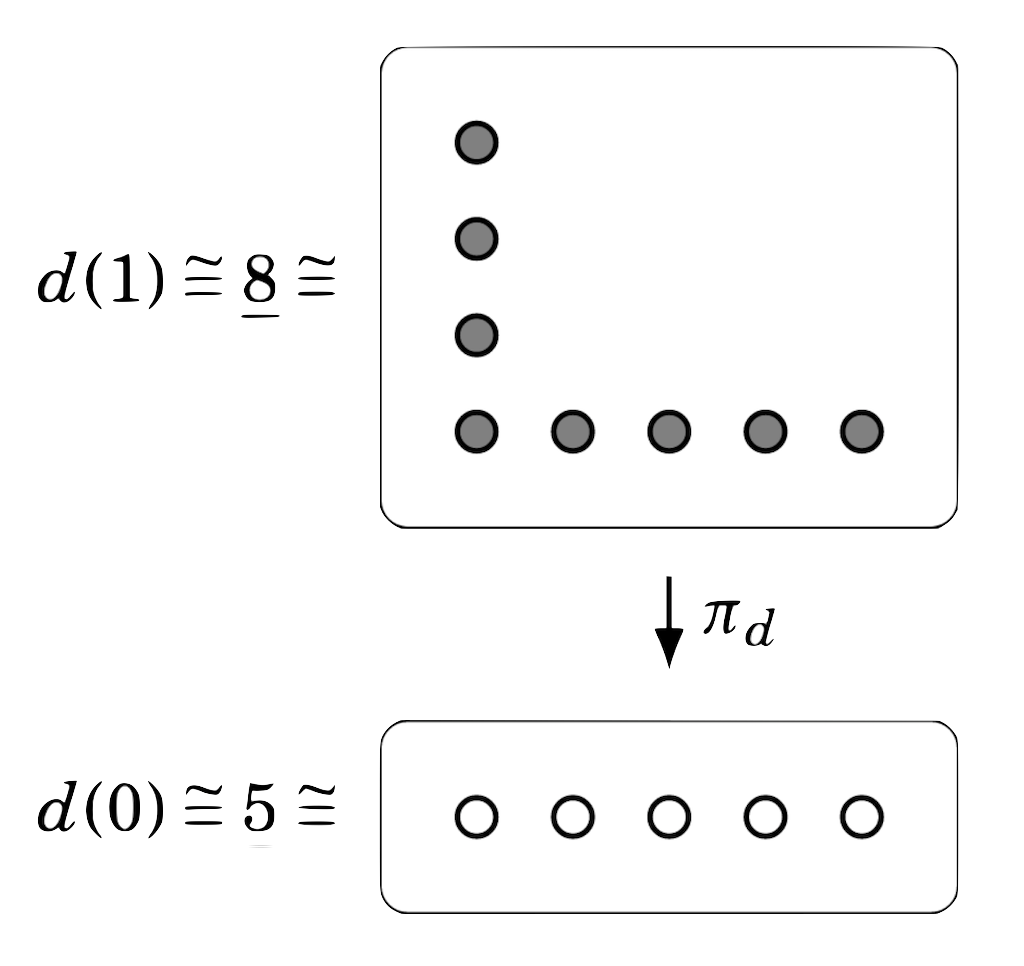
With this picture, we can now start thinking about how Dirichlet polynomials correspond to probability distributions: d(\mathcal{y})=4^\mathcal{y}+4 describes a scenario with 5 outcomes, where the first happens four times as often as the others. That is, we think of elements of d(0) as outcomes, and elements of d(1) as draws; the function \pi_d tells us which draws lead to which outcomes; the (cardinality of the) fibre \pi_d^{-1}(i) tells us the number of draws that lead to the i-th outcome. Putting this all together, we get a probability distribution on d(0), where \mathbb{P}(X=i) = \frac{|\pi_d^{-1}(i)|}{\sum\nolimits_{i\in d(0)}|\pi_d^{-1}(i)|} (since \sum_{i\in d(0)}|\pi_d^{-1}(i)|=|d(1)|). For our specific example of d(\mathcal{y})=4^\mathcal{y}+4, we obtain the probability distribution \{\frac12,\frac18,\frac18,\frac18,\frac18\}.
Looking at the picture, we can also sort of see why we chose to call A(d) the area: we showed that it was equal to |d(1)|, and this is the “area” of the top set (in terms of the number of dots), but why did we call W(d) the width? Here the “width” of the bundle looks like it should be equal to 5, not 4…
Well here’s the nice twist: let’s draw a new bundle, which does have “width” equal to 4, and “area” equal to 8, with no empty space anywhere.
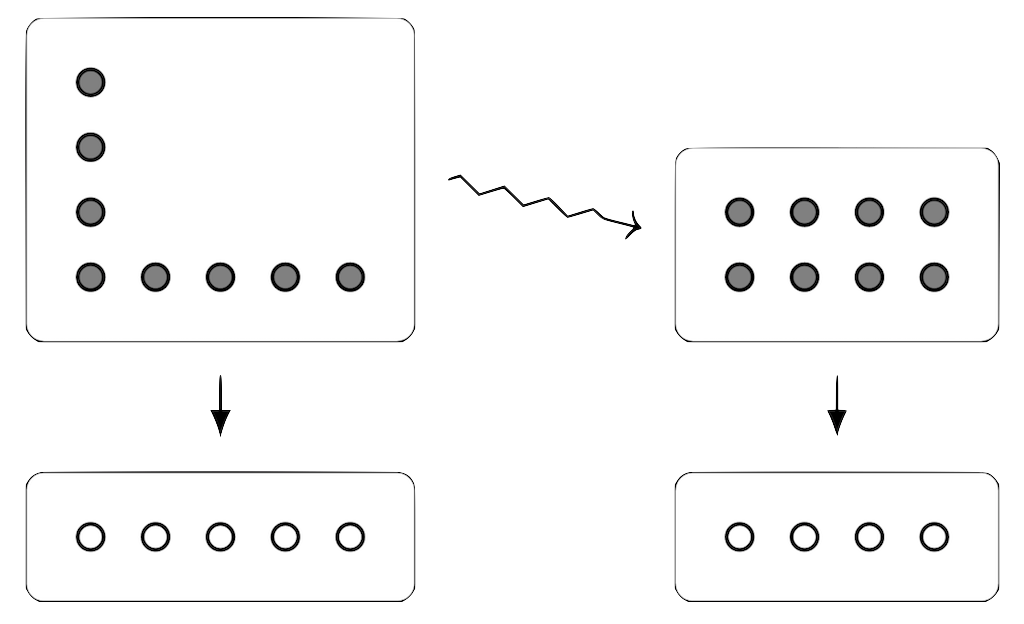
This new bundle clearly describes an entirely different scenario: for a start, we only have 4 outcomes now instead of 5. But it actually tells us something about our original bundle!
We can imagine the probability distribution described by the original bundle as telling us about an “alphabet” (or, more precisely, a coding scheme) used for sending messages: we have 5 letters (say A, B, C, D, and E), and the first letter occurs (on average, over long enough messages) four times as often as the others. This doesn’t seem very efficient though — we’re going to waste a lot of space repeating A over and over. Surely we can do better?
Of course, we can! Huffman showed [5] that, for long enough messages, the eponymous Huffman coding is optimal (caveat: among compression methods that encode symbols separately). And, as you might now expect, the Huffman coding for the example we’ve been working with has… 4 letters! In fact, this turns out to be true in general: the new bundle that we get from the area and width of the original Dirichlet polynomial describes the Huffman coding.
To make this precise we need to, finally, talk about entropy. But guess what? We already have!
5 Oh look, it’s entropy!
Something that you probably learnt very early on in life is the formula for finding the area of a rectangle: “area is equal to length times width”. Well, we’ve defined something called area, and something called width, so what do we get if we divide the former by the latter, and call the result the length? This leads to the main result of our paper.
In other words:
What is particularly nice is the fact that we can recover entropy entirely from the rig homomorphism h\colon\mathsf{Dir}\to\mathsf{Rect}, which means that we have a notion of entropy that is homomorphic in both the product and the sum of distributions, compared to the direct definition of entropy which is only homomorphic in the product.
Although we haven’t given any proofs here, all of the proofs turn out to be satisfyingly simple, and there aren’t really any sneaky tricks anywhere at all. Even so, if you’ve enjoyed this post, then consider having a look at the preprint (it’s only 15 pages long), where we give more examples, more lemmas, and briefly talk about cross entropy as well.